普拉特解析学习笔记()
原理分析
Pratt Parser是一种自顶向下的语法分析器,主要原理有:
测试过程分析
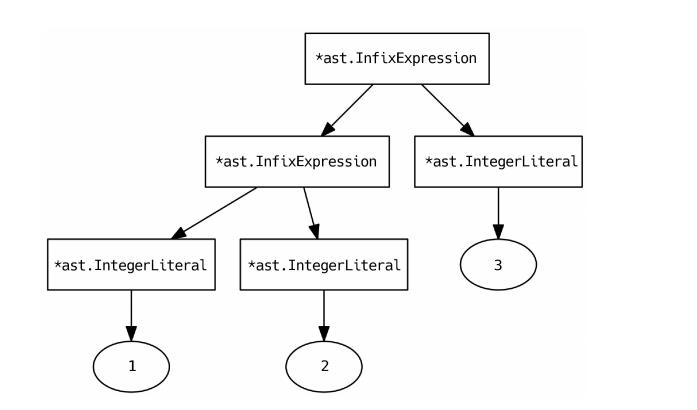
比如测试用例是
1+2+3 => ((1+2)+3)
我们需要将该表达式构建一棵语法树如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| func TestOperatorPrecedenceParsing(t *testing.T) {
opTests := []struct {
input string
expected string
}{
{
"1+2+3",
"((1+2)+3)",
},
}
for _, tt := range opTests {
l := lexer.New(tt.input)
p := New(l)
program := p.ParseProgram()
checkParserErrors(t, p)
actual := program.String()
if actual != tt.expected {
t.Errorf("expected=%q, got=%q", tt.expected, actual)
}
}
}
|
整个的函数调用栈

ParseProgram中首先声明创建一个ast.Program,作为AST的根节点
循环解析每一个statement,当碰到终止符时停止循环
1
2
3
4
5
6
7
8
9
10
11
12
13
| func (p *Parser) ParseProgram() *ast.Program {
program := &ast.Program{}
program.Statements = []ast.Statement{}
for p.curToken.Type != token.EOF {
stmt := p.parseStatement()
if stmt != nil {
program.Statements = append(program.Statements, stmt)
}
p.nextToken()
}
return program
}
|
在parseStatement函数中,然后选择Statement类型
1
2
3
4
5
6
7
8
9
10
11
| func (p *Parser) parseStatement() ast.Statement {
switch p.curToken.Type {
case token.LET:
return p.parseLetStatement()
case token.RETURN:
return p.parseReturnStatement()
default:
return p.parseExpressionStatement()
}
}
|
在parseExpressionStatement中,首先创建ast.ExpressionStatement这个结构体,然后以最低优先级(LOWEST)调用解析函数parseExpression函数(因为是普通的Expression,所以直接使用最低优先级即可)
1
2
3
4
5
6
7
8
9
10
11
12
| func (p *Parser) parseExpressionStatement() *ast.ExpressionStatement {
stmt := &ast.Expression Statement{
Token: p.curToken,
}
stmt.Expression = p.parseExpression(LOWEST)
if p.peekTokenIs(token.SEMICOLON) {
p.nextToken()
}
return stmt
}
|
调用parseExpression函数中,首先根据curToken的类型处理成对应的Expression
然后进入普拉特语法解析器,如果不满足直接返回上述生成的Expression
- 判断是否为分号,以及判断peekToken的优先级
- 取中缀表达式进行解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| func (p *Parser) parseExpression(precedence int) ast.Expression {
prefix := p.prefixParseFns[p.curToken.Type]
if prefix == nil {
p.noPrefixParseFnError(p.curToken.Type)
return nil
}
leftExp := prefix()
for !p.peekTokenIs(token.SEMICOLON) && precedence < p.peekPrecedence() {
infix := p.infixParseFns[p.peekToken.Type]
if infix == nil {
return leftExp
}
p.nextToken()
leftExp = infix(leftExp)
}
return leftExp
}
|
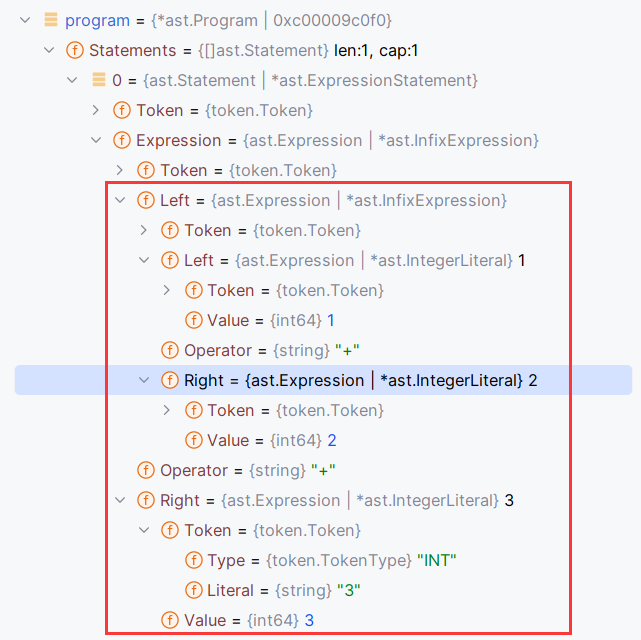
所以,在经过整个函数调用栈之后,函数参数如图所示:
参考
https://www.less-bug.com/posts/pratt-parsing-introduction-and-implementation-in-typescript/
